New Research Decomposes Sound Into 3 Basic Components
US Landmark research has huge potential for signal processing and people with sensory needs. 06/11/23

|
Exploration into harmonic phenomena began with the ancient Babylonians, who used the harmonic series to map the stars.
From these primeval beginnings we travel to 18th & 19th century Europe, where the work of Alexis Clairaut, Joseph Louis Lagrange and yes, Joseph Fourier really kicked things off by not only modeling, in mathematical numbers, astronomical measurements (like Clairaut's computation of our moon's orbit) but also, musical matters (like Lagrange's computation of a vibrating string).
Fourier's crucial contribution was to suggest that any arbitrary sound, no matter how complex, could be represented by, or broken down into, a series of sine (and cosine) waves by using a "Fourier transform."
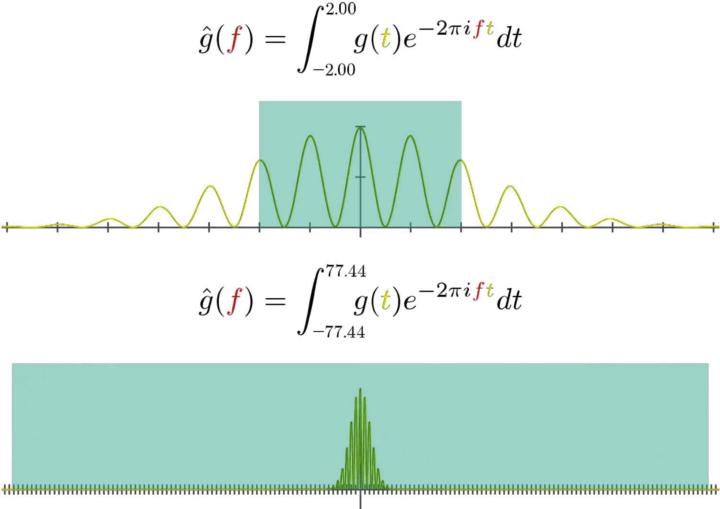
In Mathematics, other examples of transforms include the flipping or rotating of a shape, but Fourier's transform (if we could see it) is more like a prism that splits the input sound into a number of different frequencies, just like how a prism might split white light into a number of different colours. In 1965, the "Fast" Fourier Transform made it possible for computers to analyse complex signals and manipulate them, becoming a crucial keystone of future acoustic research.
This brings us to 2023, where Doctoral researcher Leonardo Fierro and professor Vesa Välimäki have been refining previous studies into a new complex model of sound, as perceived by human beings.
Some sounds; wind instruments, breathy voices, anything with lots of inharmonic noise, are tricky to model with the harmonic series alone, requiring hundreds of tiny sine waves to replicate the signal. A two component model of sines and variable noise combined will more authentically model these sounds, but ideally, a third component known as "transient" (little clicky sounds) would be added too, especially when modeling human speech.
Leonardo Fierro and Vesa Välimäki from the Acoustics Lab, Aalto University, Finland, realised that how human beings hear these three components (the separate clicks, whistles and hisses) is crucial when modeling sound. Stretched-out clicks may be perceived as a ringing or noisy sound; conversely, short blips may lose their sense of pitch.
https://www.aes.org/e-lib/browse.cfm?elib=22152
The team's optimised model utilises this insight in the following way: At any one moment, the sound is either allowed to be a sine or a transient; not both at once. Noise can be freely mixed with either, and works as a kind of smoothing, smudging presence, creating nuances not captured by the other components.
Fierro said: "It's like finding the missing piece of a puzzle to connect those two parts that did not fit together before,"
In a listening test, this new method emerged as the winner when decomposing most sounds, based on listener feedback. Though it does struggle a little with vibrato, so maybe AI Pavarotti is still a few years off.
Obvious uses for this technology include resynthesis, distortion-free compression (by reducing transients) and new high-quality time-stretching algorithms:
"The new sound decomposition method opens many exciting possibilities in sound processing," said Välimäki. "The slowing down of sound is currently our main interest. It is striking that for example in sports news, the slow-motion videos are always silent. The reason is probably that the sound quality in current slow-down audio tools is not good enough. We have already started developing better time-scale modification methods, which use a deep neural network to help stretch some components."
Yet, as someone who suffers from Misophonia, a form of selective sound sensitivity; often a feature of Autism, another use struck me. Current noise-cancelling headphones work by utilising small built in microphones that record the ambient noise, invert it's phase (I guess, by flipping it upside down or adding a small delay), and then mix that inverted signal into the music you are listening to.
It's super clever, but this current method has some limitations. It works best with lower frequency background noise and struggles with higher, more random frequencies (like the chatter of a busy coffee shop), and it also tries to cancel out everything, it's non-selective.
So I mused, what would happen if this new algorithm could be trained by the user, to learn which sounds are bearable and which are irritating, then only cancel those? Some physical limitations would need to be overcome, you don't want to wear big headphones all day (these are currently the most effective due to soundproof earcups) but the possibilities are there to explore!
Posted by MagicalSynthAdventure an expert in synthesis technology from last Century and Amiga enthusiast.

- Koji Kondo's Hidden Motifts, Themes, and Tropes 03-May-24
- Ten Years Getting High in the Prodigy 03-May-24
- Justice: Hyperdrama, Creative Process, & Tame Impala 03-May-24
- The History of Drum Machines 26-Apr-24
- The MiniMoog Book Gets Funded 25-Apr-24
Even more news...
Want Our Newsletter?
More...
 Raspberry PI5 Hardware VST Host
Raspberry PI5 Hardware VST Host
Floyd Steinberg gets the gear together

VST Live 2 and Live Performing
 3 Home Keyboards that are Actually AWESOME Synths!
3 Home Keyboards that are Actually AWESOME Synths!
Not somewhere you usually look...

Play V-collection sounds in standalone
 3 Maverick Synth Makers who Did it for Themselves
3 Maverick Synth Makers who Did it for Themselves
Innovation is the main focus for these builders.
 Modal Is Back - Restructuring Complete
Modal Is Back - Restructuring Complete
Website up - Modal app support back too